
機械学習に挑戦(4)
NNCの学習結果をC/C++で使ってみる
どもです。
前回のエントリで、画像が「『0』~『9』のどの数字か」を判別してみました。
こうなってくると次は、この学習結果を使用して、任意の画像を判別してみたくなるのが「エンジニアの性」であると思います。
そこで今回は、前回のエントリの末尾で宣言した通り、学習モデルのC/C++での使用に挑戦してみます。
1. 作業環境
今回のエントリでは、以下の環境で作業を実施します。
| 項目 | 内容 |
|---|---|
| OS | Windows10 Pro 64bit (21H1) |
| CPU | i7-8700 |
| メモリ | 16GB |
| IDE | Visual Studio Community 2019 Version 16.11.8 |
| OpenCV | Ver. 4.5.5 vc15/x64向けビルド |
| NNabla C Runtime | Ver. 1.24.0 |
今回使用する環境の中で、「OpenCV」と「NNabla C Runtime」は初出です。
(OpenCVについては、別のエントリで出てきた記憶はありますが、別のシリーズということで…。)
「OpenCV」は、画像解析を行う際に使用するライブラリの中で最も有名かと思います。
インストールやビルドなどの情報は、公式ページおよびリリースページ、またはネットの情報に任せて、本エントリでは割愛します。
「NNabla C Runtime」は、NNCでの学習結果を使用するために必要な環境(ライブラリ)です。
取得方法やビルド手順については、後ほど記載します。
2. モデルのエクスポート
まず、学習結果のモデルをエクスポートします。
NNCで作成済みのモデルは、以下の手順でエクスポートできます。
- NNCを起動する
- エクスポートしたい学習結果を含むプロジェクトを開く
- 「学習結果リスト」の任意の学習結果上で右クリックし、
[エクスポート]-[NNB(NNabla C Runtime file format)]
を選択する
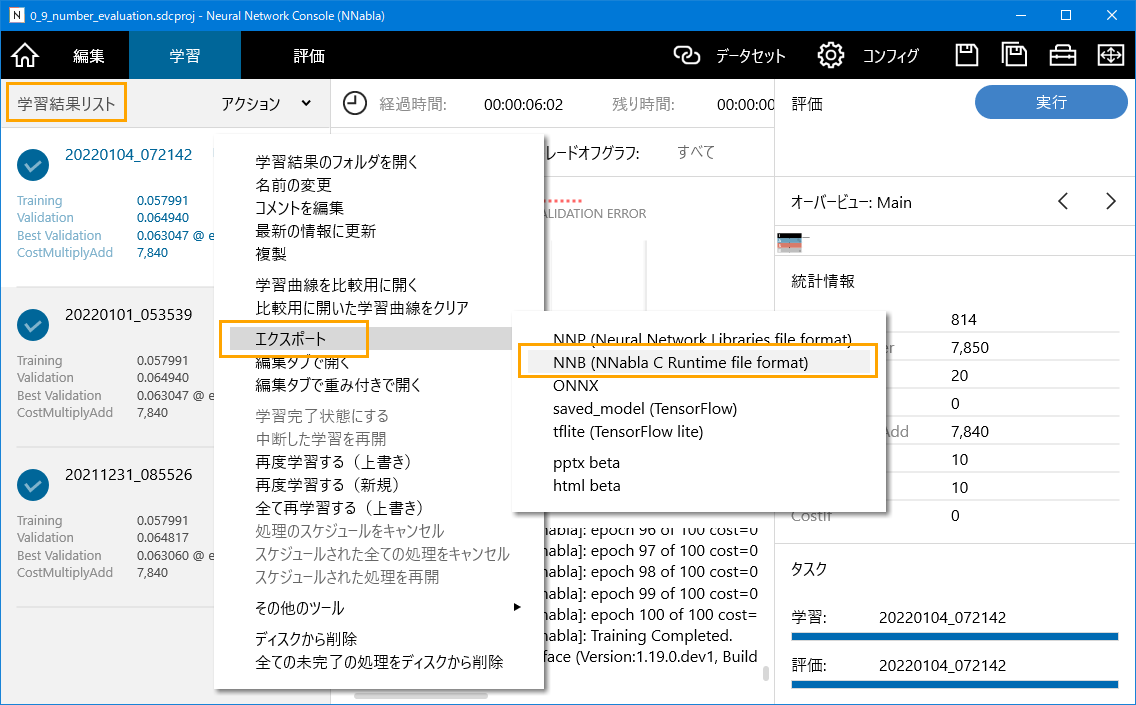
この手順を実施することで、学習結果のモデル(.nnb)およびC言語のソースコードが出力されます。
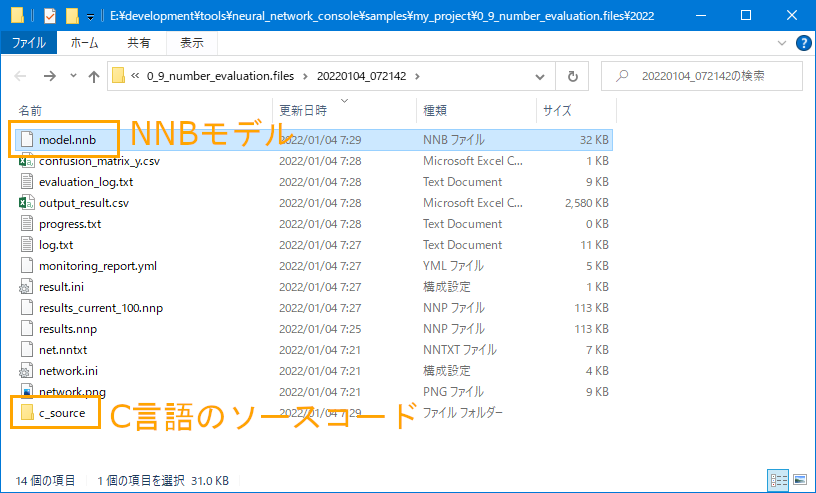
なお、今回のエントリでは学習結果のモデル(.nnb)は使用しません。
ソースコードのみを使用します。
3. NNabla C Runtime
エクスポートした学習結果のモデルとソースコードを使用するためには、対応する環境が必要です。
この環境が「NNabla C Runtime」であり、ネットで公開されています。
この環境を構築する手順を記載します。
3.1. ソースコードの取得
NNabla C Runtimeは、GitHubで公開されています。
GitHubをクローンする、あるいは環境一式をダウンロードして取得します。
3.2. ソースコード(ライブラリ)のビルド
ソースコードが取得できたら、それらをビルドします。
今回は、VisualStudioを使用してのビルドですので、クローンした環境の中の以下のバッチファイルを実行すればビルド自体は実施できます。
nnabla-c-runtime\build-tools\msvc\build.bat
しかしながら実は、このbatファイルをそのまま実行した場合、VisualStudioCommunity2019ではビルドができません。
VisualStudioCommunity2019を使用してビルドするためには、上述のbatファイルの20行目を以下のように修正します。
変更前
SET GENERATETARGET=Visual Studio 14 2015 Win64
変更後
SET GENERATETARGET=Visual Studio 16 2019
なお、開発環境がVisualStudio2015の場合には、この変更は必要ありません。
GENERATETARGETにセットする値は、各人の開発環境/使用したい環境に合せて適宜変更、設定してください。
この設定が完了した後は、やはりbatファイルを実行すればOKです。
ビルドが完了すると、以下の成果物が出力されます。
nnabla-c-runtime\build\nnabla-c-runtime-1.2.0.dev1_c1-win64.zip
このzipファイルを解凍すれば、必要なファイル(.libや.h)が取得できます。
以上で、「NNabla C Runtime」のビルドは完了です。
4. コードの編集
モデルのエクスポートで書いた通り、NNCではモデルと(NNBファイル)と一緒に、それに対応するC言語のソースコードが出力されます。
出力されるコードは、以下の5つになります。
| ファイル名 | 内容 |
|---|---|
| MainRuntime_example.c | main関数 推論を行う一連の処理の呼び出しや推論対象データの読出し、推論データの書込み処理が実装されている。 |
| MainRuntime_inference.c/.h | 実際に推論を行う処理を実装している。 |
| MainRuntime_parameters.c/.h | 推論を行う際に使用するパラメータが格納されている。 (内容を見たカンジだと、学習結果のマトリクス?が出力されている様子。) |
ところでこのコードですが、「そのまま使用できて、ビルドもできるだろう。また、実行すればそのまま推論できるだろう」と考えてしまうのが「フツー」だと思います。
しかし実際は、「そのまま使うことはできません」。
もちろん、「そのまま使うことができる」場合もあると思います。
しかしながら今回は、少なくとも前回のエントリで示したような、画像の中の数字の推論はできません。
(できませんでした。)
4.1. 使用できない原因
まず、生成されたコードがそのまま使用できない「原因」です。
それは…
推論モデルに渡すデータが、学習結果のモデルへの入力と一致していないから
です。
どういうことかというと、生成されたコードでは、推論対象のデータ(今回の場合はPNGの画像)を以下のコードで読み込んでいます。
// Input files.
FILE* input0 = fopen(argv[1], "rb");
assert(input0);
int input_read_size0 = fread(nnablart_mainruntime_input_buffer(context, 0), sizeof(float), NNABLART_MAINRUNTIME_INPUT0_SIZE, input0);
assert(input_read_size0 == NNABLART_MAINRUNTIME_INPUT0_SIZE);
fclose(input0);
ここで「nnablart_mainruntime_input_buffer(context, 0)」は、推論対象の入力データを格納するバッファへのポインタを返す関数です。
本体は、「MainRuntime_inference.c」に実装されています。
見てわかるように、生成されたコードではPNGファイルをそのままバイナリファイルとして読み込み、そのファイルの内容全体を「推論対象」としています。
しかしながら、PNGファイルはフォーマットが決まっており、全てが画像そのもののデータというわけではありません。
そのため、上記のコードのようにファイル全体を推論対象としてしまうと、画像データ以外のデータも推論対象となってしまい、適切に推論が行われません。
加えて書いておくと、MNISTが提供している画像データを使用した場合、上述のコードの「fread」が返す値は、「NNABLART_MAINRUNTIME_INPUT0_SIZE」の値と一致しませんでした。
そのため、DEBUGモードでステップ実行してみると、fread直後のassertでエラーになります。
4.2. 使用できるようにする
では、生成されたコードを使用できるように修正して…はイケマセン。
生成されたコードの先頭部分には、以下の記載があります。
THIS FILE IS AUTO-GENERATED BY CODE GENERATOR.
PLEASE DO NOT EDIT THIS FILE BY HAND!
…仕方ないので、MainRuntime_example.c の代替コードを自分で実装することにします。
4.3. 実装
早速ですが、代替コードとして実装したコードを示します。
#include <Windows.h>
#include <tchar.h>
#include "opencv2/opencv.hpp"
#include "MainRuntime_inference.h"
#include "MainRuntime_parameters.h"
int main(int argc, char* argv[])
{
cv::Mat image;
image = cv::imread(arg1);
if (image.empty()) {
return 0;
}
cv::Mat grayImage;
cv::cvtColor(image, grayImage, cv::COLOR_BGR2GRAY);
// Allocate and initialize context
void *context = nnablart_mainruntime_allocate_context(MainRuntime_parameters);
//Copy data to buffer
BYTE* src = (BYTE*)grayImage.data;
FLOAT* dst = (FLOAT*)nnablart_mainruntime_input_buffer(context, 0);
for (ULONG index = 0; index < NNABLART_MAINRUNTIME_INPUT0_SIZE; index++) {
float float_data = *(src + index);
*(dst + index) = float_data / ((float)255.0);
}
// Exec inference
nnablart_mainruntime_inference(context);
_tprintf(_T("TARGET PATH = %s\n"), arg1.c_str());
for (int index = 0; index < NNABLART_MAINRUNTIME_OUTPUT0_SIZE; index++) {
_tprintf(_T("%3d : %.4f\n"), index, *(output_buffer + index));
}
// free all context
nnablart_mainruntime_free_context(context);
return 0;
}
基本的な処理の流れは、生成されたコードと同じです。
変更した内容は、以下の通りです。
- 推論対象の画像データは、OpenCvを用いて読出しと変更(グレースケール化)を行う。
- グレースケール化したデータを、浮動小数点型(0.0~1.0)に変換する。
- 推論結果は、コマンドライン上に出力する。
これらの処理について、簡単にですが内容を説明します。
4.3.1. グレースケール化
まず、画像のグレースケール化です。
推論を行うモデルでは、入力データのサイズを「1x28x28」としています。
対して、MNISTが公開している画像データは、(見た目こそ白黒/グレーですが)RGBの3チャンネルの画像です。(3x28x28)
データのサイズ(型?)が一致していません。
この不一致を解消するために、グレースケール化を行います。
4.3.2. 浮動小数点化
これも、モデルとデータの型の不一致の解消のための手順です。
推論を行うモデルが使用するデータは、0~1の間の値です。
しかし、グレースケール化したデータは、0~255の間の値となっています。
この不一致を解消するために、データ型を変換します。
4.3.3. 推論結果の出力
これについては、特に書くことはありません。
ファイル出力からコマンドライン出力に変更しただけです。
なお推論結果は、「どの程度数字に一致しているか」を示す値が、「0」~「9」の順番でそれぞれ出力されます。
5. やってみよう
5.1. 実装したコードを
それでは、実際に動かしてみます。
まずは、「9」が書かれたデータで試してみます。
で、結果が以下!

「9」が書かれた画像を入力した場合、「9」の値(推論値)が最も大きくなっており、正しく推論ができていることが分かります。
5.2. 他の数値もやってみる
次に「9」以外の数値についても、推論させてみました。
で、その結果が以下!
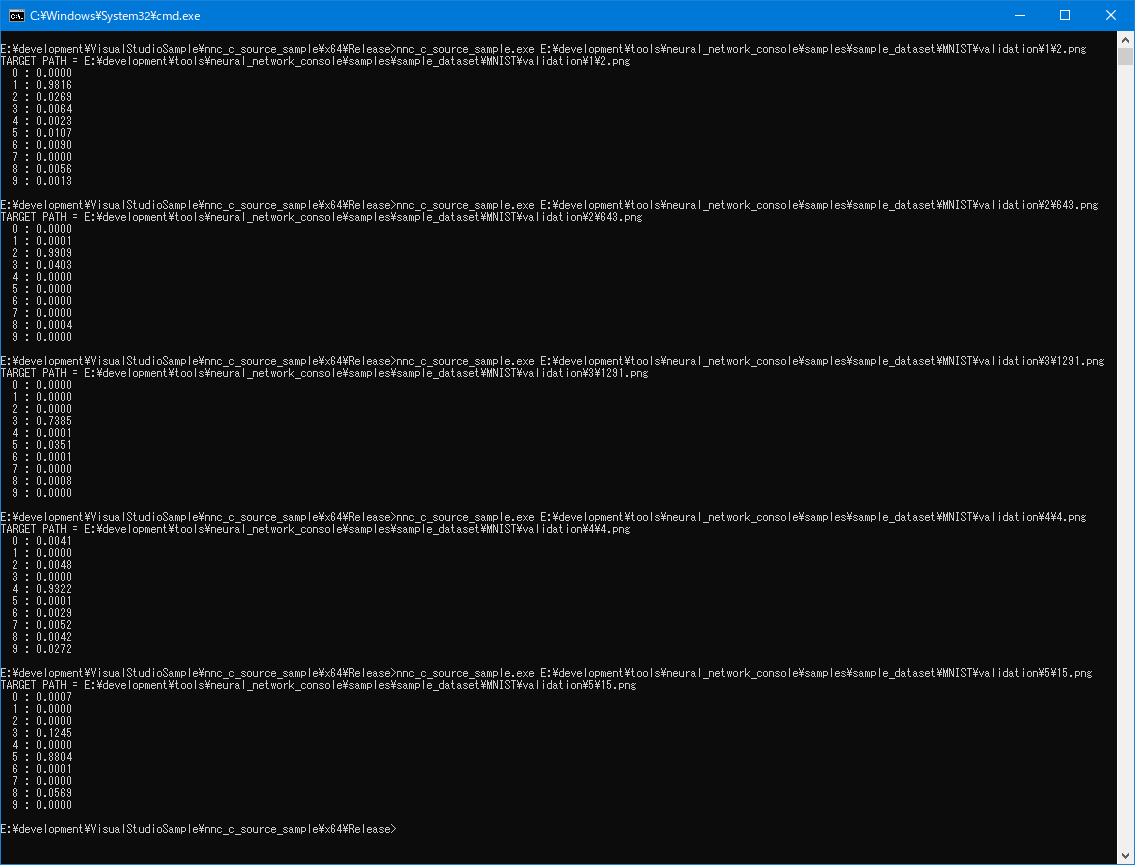
試した画像全てにおいて、適切に推論ができていることが分かります。
6. まとめ
今回は、前回のエントリで作成したモデルを、C/C++で使用してみました。
NNCから生成されたコードは、一部分、特に推論モデルの入力に合致するようにデータを加工する部分は自分で実装する必要はありますが、殆どそのまま使用でき、簡単に推論を行うプログラムを作成できます。
なお今回のエントリで試した推論では、その「推論値」については言及していません。
この値は、本来「推論値がどの程度正確か」を示す値なので、この値をちゃんと確認する必要があります。
しかし、この値の確認は、「モデルをC/C++で使ってみる」というエントリの目的から外れてしまうため、あえて確認を省略しています。
実際にモデルを運用する場合には、この値もキチンと確認するようにしましょう!
ではっ!